Nucleotide

This nucleotide contains the five-carbon sugar deoxyribose (at center), a nitrogenous base called adenine (upper right), and one phosphate group (left). The deoxyribose sugar joined only to the nitrogenous base forms a Deoxyribonucleoside called deoxyadenosine, whereas the whole structure along with the phosphate group is a nucleotide, a constituent of DNA with the name deoxyadenosine monophosphate.
Nucleotides are organic molecules that serve as the monomer units for forming the nucleic acid polymers deoxyribonucleic acid (DNA) and ribonucleic acid (RNA), both of which are essential biomolecules within all life-forms on Earth. Nucleotides are the building blocks of nucleic acids; they are composed of three subunit molecules: a nitrogenous base (also known as nucleobase), a five-carbon sugar (ribose or deoxyribose), and at least one phosphate group.
A nucleoside is a nitrogenous base and a 5-carbon sugar. Thus a nucleoside plus a phosphate group yields a nucleotide.
Nucleotides also play a central role in metabolism at a fundamental, cellular level. They carry packets of chemical energy—in the form of the nucleoside triphosphates Adenosine triphosphate (ATP), Guanosine triphosphate (GTP), Cytidine triphosphate (CTP) and Uridine triphosphate (UTP)—throughout the cell to the many cellular functions that demand energy, which include: synthesizing amino acids, proteins and cell membranes and parts, moving the cell and moving cell parts (both internally and intercellularly), dividing the cell, etc.[1] In addition, nucleotides participate in cell signaling (cyclic guanosine monophosphate or cGMP and cyclic adenosine monophosphate or cAMP), and are incorporated into important cofactors of enzymatic reactions (e.g. coenzyme A, FAD, FMN, NAD, and NADP+).
In experimental biochemistry, nucleotides can be radiolabeled with radionuclides to yield radionucleotides.
Contents
1 Structure
2 Synthesis
2.1 Pyrimidine ribonucleotide synthesis
2.2 Purine ribonucleotide synthesis
2.3 Pyrimidine and purine degradation
3 Unnatural base pair (UBP)
4 Length unit
5 Nucleotide supplements
6 Abbreviation codes for degenerate bases
7 See also
8 References
9 Further reading
10 External links
Structure
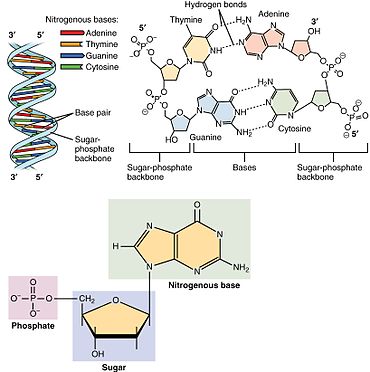
Showing the arrangement of nucleotides within the structure of nucleic acids: At lower left, a monophosphate nucleotide; its nitrogenous base represents one side of a base-pair. At upper right, four nucleotides form two base-pairs: thymine and adenine (connected by double hydrogen bonds) and guanine and cytosine (connected by triple hydrogen bonds). The individual nucleotide monomers are chain-joined at their sugar and phosphate molecules, forming two 'backbones' (a double helix) of a nucleic acid, shown at upper left.
A nucleotide is composed of three distinctive chemical sub-units: a five-carbon sugar molecule, a nitrogenous base—which two together are called a nucleoside—and one phosphate group. With all three joined, a nucleotide is also termed a "nucleoside monophosphate". The chemistry sources ACS Style Guide[2] and IUPAC Gold Book[3] prescribe that a nucleotide should contain only one phosphate group, but common usage in molecular biology textbooks often extends the definition to include molecules with two, or with three, phosphates.[1][4][5][6] Thus, the terms "nucleoside diphosphate" or "nucleoside triphosphate" may also indicate nucleotides.
Nucleotides contain either a purine or a pyrimidine base—i.e., the nitrogenous base molecule, also known as a nucleobase—and are termed ribonucleotides if the sugar is ribose, or deoxyribonucleotides if the sugar is deoxyribose. Individual phosphate molecules repetitively connect the sugar-ring molecules in two adjacent nucleotide monomers, thereby connecting the nucleotide monomers of a nucleic acid end-to-end into a long chain. These chain-joins of sugar and phosphate molecules create a 'backbone' strand for a single- or double helix. In any one strand, the chemical orientation (directionality) of the chain-joins runs from the 5'-end to the 3'-end (read: 5 prime-end to 3 prime-end)—referring to the five carbon sites on sugar molecules in adjacent nucleotides. In a double helix, the two strands are oriented in opposite directions, which permits base pairing and complementarity between the base-pairs, all which is essential for replicating or transcribing the encoded information found in DNA.
Unlike in nucleic acid nucleotides, singular cyclic nucleotides are formed when the phosphate group is bound twice to the same sugar molecule, i.e., at the corners of the sugar hydroxyl groups.[1] These individual nucleotides function in cell metabolism rather than the nucleic acid structures of long-chain molecules.
Nucleic acids then are polymeric macromolecules assembled from nucleotides, the monomer-units of nucleic acids. The purine bases adenine and guanine and pyrimidine base cytosine occur in both DNA and RNA, while the pyrimidine bases thymine (in DNA) and uracil (in RNA) in just one. Adenine forms a base pair with thymine with two hydrogen bonds, while guanine pairs with cytosine with three hydrogen bonds.
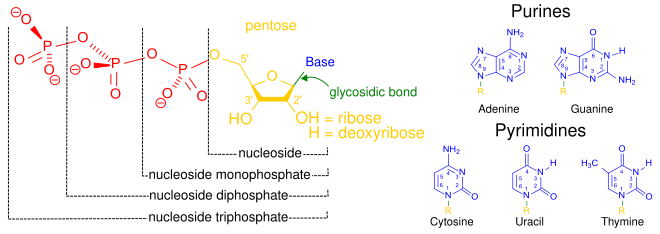
Structural elements of three nucleotides—where one-, two- or three-phosphates are attached to the nucleoside (in yellow, blue, green) at center: 1st, the nucleotide termed as a nucleoside monophosphate is formed by adding a phosphate group (in red); 2nd, adding a second phosphate group forms a nucleoside diphosphate; 3rd, adding a third phosphate group results in a nucleoside triphosphate. + The nitrogenous base (nucleobase) is indicated by "Base" and "glycosidic bond" (sugar bond). All five primary, or canonical, bases—the purines and pyrimidines—are sketched at right (in blue).
Synthesis
Nucleotides can be synthesized by a variety of means both in vitro and in vivo.
In vitro, protecting groups may be used during laboratory production of nucleotides. A purified nucleoside is protected to create a phosphoramidite, which can then be used to obtain analogues not found in nature and/or to synthesize an oligonucleotide.
In vivo, nucleotides can be synthesized de novo or recycled through salvage pathways.[7] The components used in de novo nucleotide synthesis are derived from biosynthetic precursors of carbohydrate and amino acid metabolism, and from ammonia and carbon dioxide. The liver is the major organ of de novo synthesis of all four nucleotides. De novo synthesis of pyrimidines and purines follows two different pathways. Pyrimidines are synthesized first from aspartate and carbamoyl-phosphate in the cytoplasm to the common precursor ring structure orotic acid, onto which a phosphorylated ribosyl unit is covalently linked. Purines, however, are first synthesized from the sugar template onto which the ring synthesis occurs. For reference, the syntheses of the purine and pyrimidine nucleotides are carried out by several enzymes in the cytoplasm of the cell, not within a specific organelle. Nucleotides undergo breakdown such that useful parts can be reused in synthesis reactions to create new nucleotides.
Pyrimidine ribonucleotide synthesis
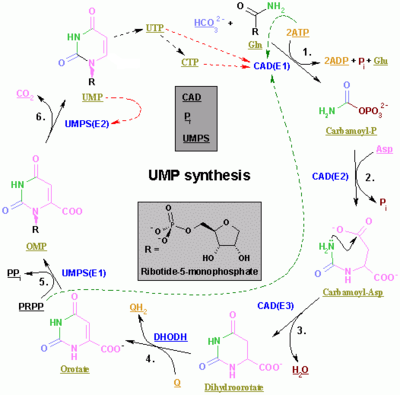
The synthesis of UMP.
The synthesis of the pyrimidines CTP and UTP occurs in the cytoplasm and starts with the formation of carbamoyl phosphate from glutamine and CO2. Next, aspartate carbamoyltransferase catalyzes a condensation reaction between aspartate and carbamoyl phosphate to form carbamoyl aspartic acid, which is cyclized into 4,5-dihydroorotic acid by dihydroorotase. The latter is converted to orotate by dihydroorotate oxidase. The net reaction is:
- (S)-Dihydroorotate + O2 → Orotate + H2O2
Orotate is covalently linked with a phosphorylated ribosyl unit. The covalent linkage between the ribose and pyrimidine occurs at position C1[8] of the ribose unit, which contains a pyrophosphate, and N1 of the pyrimidine ring. Orotate phosphoribosyltransferase (PRPP transferase) catalyzes the net reaction yielding orotidine monophosphate (OMP):
- Orotate + 5-Phospho-α-D-ribose 1-diphosphate (PRPP) → Orotidine 5'-phosphate + Pyrophosphate
Orotidine 5'-monophosphate is decarboxylated by orotidine-5'-phosphate decarboxylase to form uridine monophosphate (UMP). PRPP transferase catalyzes both the ribosylation and decarboxylation reactions, forming UMP from orotic acid in the presence of PRPP. It is from UMP that other pyrimidine nucleotides are derived. UMP is phosphorylated by two kinases to uridine triphosphate (UTP) via two sequential reactions with ATP. First the diphosphate form UDP is produced, which in turn is phosphorylated to UTP. Both steps are fueled by ATP hydrolysis:
- ATP + UMP → ADP + UDP
- UDP + ATP → UTP + ADP
CTP is subsequently formed by amination of UTP by the catalytic activity of CTP synthetase. Glutamine is the NH3 donor and the reaction is fueled by ATP hydrolysis, too:
- UTP + Glutamine + ATP + H2O → CTP + ADP + Pi
Cytidine monophosphate (CMP) is derived from cytidine triphosphate (CTP) with subsequent loss of two phosphates.[9][10]
Purine ribonucleotide synthesis
The atoms that are used to build the purine nucleotides come from a variety of sources:

The synthesis of IMP. The color scheme is as follows: enzymes, coenzymes, substrate names, metal ions, inorganic molecules
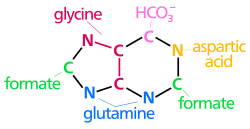 | The biosynthetic origins of purine ring atoms N1 arises from the amine group of Asp C2 and C8 originate from formate N3 and N9 are contributed by the amide group of Gln C4, C5 and N7 are derived from Gly C6 comes from HCO3− (CO2) |
The de novo synthesis of purine nucleotides by which these precursors are incorporated into the purine ring proceeds by a 10-step pathway to the branch-point intermediate IMP, the nucleotide of the base hypoxanthine. AMP and GMP are subsequently synthesized from this intermediate via separate, two-step pathways. Thus, purine moieties are initially formed as part of the ribonucleotides rather than as free bases.
Six enzymes take part in IMP synthesis. Three of them are multifunctional:
GART (reactions 2, 3, and 5)
PAICS (reactions 6, and 7)
ATIC (reactions 9, and 10)
The pathway starts with the formation of PRPP. PRPS1 is the enzyme that activates R5P, which is formed primarily by the pentose phosphate pathway, to PRPP by reacting it with ATP. The reaction is unusual in that a pyrophosphoryl group is directly transferred from ATP to C1 of R5P and that the product has the α configuration about C1. This reaction is also shared with the pathways for the synthesis of Trp, His, and the pyrimidine nucleotides. Being on a major metabolic crossroad and requiring much energy, this reaction is highly regulated.
In the first reaction unique to purine nucleotide biosynthesis, PPAT catalyzes the displacement of PRPP's pyrophosphate group (PPi) by an amide nitrogen donated from either glutamine (N), glycine (N&C), aspartate (N), folic acid (C1), or CO2. This is the committed step in purine synthesis. The reaction occurs with the inversion of configuration about ribose C1, thereby forming β-5-phosphorybosylamine (5-PRA) and establishing the anomeric form of the future nucleotide.
Next, a glycine is incorporated fueled by ATP hydrolysis and the carboxyl group forms an amine bond to the NH2 previously introduced. A one-carbon unit from folic acid coenzyme N10-formyl-THF is then added to the amino group of the substituted glycine followed by the closure of the imidazole ring. Next, a second NH2 group is transferred from a glutamine to the first carbon of the glycine unit. A carboxylation of the second carbon of the glycin unit is concomittantly added. This new carbon is modified by the additional of a third NH2 unit, this time transferred from an aspartate residue. Finally, a second one-carbon unit from formyl-THF is added to the nitrogen group and the ring covalently closed to form the common purine precursor inosine monophosphate (IMP).
Inosine monophosphate is converted to adenosine monophosphate in two steps. First, GTP hydrolysis fuels the addition of aspartate to IMP by adenylosuccinate synthase, substituting the carbonyl oxygen for a nitrogen and forming the intermediate adenylosuccinate. Fumarate is then cleaved off forming adenosine monophosphate. This step is catalyzed by adenylosuccinate lyase.
Inosine monophosphate is converted to guanosine monophosphate by the oxidation of IMP forming xanthylate, followed by the insertion of an amino group at C2. NAD+ is the electron acceptor in the oxidation reaction. The amide group transfer from glutamine is fueled by ATP hydrolysis.
Pyrimidine and purine degradation
In humans, pyrimidine rings (C, T, U) can be degraded completely to CO2 and NH3 (urea excretion). That having been said, purine rings (G, A) cannot. Instead they are degraded to the metabolically inert uric acid which is then excreted from the body. Uric acid is formed when GMP is split into the base guanine and ribose. Guanine is deaminated to xanthine which in turn is oxidized to uric acid. This last reaction is irreversible. Similarly, uric acid can be formed when AMP is deaminated to IMP from which the ribose unit is removed to form hypoxanthine. Hypoxanthine is oxidized to xanthine and finally to uric acid. Instead of uric acid secretion, guanine and IMP can be used for recycling purposes and nucleic acid synthesis in the presence of PRPP and aspartate (NH3 donor).
Unnatural base pair (UBP)
An unnatural base pair (UBP) is a designed subunit (or nucleobase) of DNA which is created in a laboratory and does not occur in nature. In 2012, a group of American scientists led by Floyd Romesberg, a chemical biologist at the Scripps Research Institute in San Diego, California, published that his team designed an unnatural base pair (UBP).[11] The two new artificial nucleotides or Unnatural Base Pair (UBP) were named d5SICS and dNaM. More technically, these artificial nucleotides bearing hydrophobic nucleobases, feature two fused aromatic rings that form a (d5SICS–dNaM) complex or base pair in DNA.[12][13] In 2014 the same team from the Scripps Research Institute reported that they synthesized a stretch of circular DNA known as a plasmid containing natural T-A and C-G base pairs along with the best-performing UBP Romesberg's laboratory had designed, and inserted it into cells of the common bacterium E. coli that successfully replicated the unnatural base pairs through multiple generations.[14] This is the first known example of a living organism passing along an expanded genetic code to subsequent generations.[12][15] This was in part achieved by the addition of a supportive algal gene that expresses a nucleotide triphosphate transporter which efficiently imports the triphosphates of both d5SICSTP and dNaMTP into E. coli bacteria.[12] Then, the natural bacterial replication pathways use them to accurately replicate the plasmid containing d5SICS–dNaM.
The successful incorporation of a third base pair is a significant breakthrough toward the goal of greatly expanding the number of amino acids which can be encoded by DNA, from the existing 21 amino acids to a theoretically possible 172, thereby expanding the potential for living organisms to produce novel proteins.[14] The artificial strings of DNA do not encode for anything yet, but scientists speculate they could be designed to manufacture new proteins which could have industrial or pharmaceutical uses.[16]
Length unit
Nucleotide (abbreviated "nt") is a common unit of length for single-stranded nucleic acids, similar to how base pair is a unit of length for double-stranded nucleic acids.
Nucleotide supplements
A study done by the Department of Sports Science at the University of Hull in Hull, UK has shown that nucleotides have significant impact on cortisol levels in saliva. Post exercise, the experimental nucleotide group had lower cortisol levels in their blood than the control or the placebo. Additionally, post supplement values of Immunoglobulin A were significantly higher than either the placebo or the control. The study concluded, "nucleotide supplementation blunts the response of the hormones associated with physiological stress."[17]
Another study conducted in 2013 looked at the impact nucleotide supplementation had on the immune system in athletes. In the study, all athletes were male and were highly skilled in taekwondo. Out of the twenty athletes tested, half received a placebo and half received 480 mg per day of nucleotide supplement. After thirty days, the study concluded that nucleotide supplementation may counteract the impairment of the body's immune function after heavy exercise.[18]
Abbreviation codes for degenerate bases
The IUPAC has designated the symbols for nucleotides.[19] Apart from the five (A, G, C, T/U) bases, often degenerate bases are used especially for designing PCR primers. These nucleotide codes are listed here. Some primer sequences may also include the character "I", which codes for the non-standard nucleotide inosine. Inosine occurs in tRNAs, and will pair with adenine, cytosine, or thymine. This character does not appear in the following table however, because it does not represent a degeneracy. While inosine can serve a similar function as the degeneracy "D", it is an actual nucleotide, rather than a representation of a mix of nucleotides that covers each possible pairing needed.
| Symbol[19] | Description | Bases represented | ||||
|---|---|---|---|---|---|---|
| A | adenine | A | 1 | |||
| C | cytosine | C | ||||
| G | guanine | G | ||||
| T | thymine | T | ||||
| U | uracil | U | ||||
| W | weak | A | T | 2 | ||
| S | strong | C | G | |||
| M | amino | A | C | |||
| K | keto | G | T | |||
| R | purine | A | G | |||
| Y | pyrimidine | C | T | |||
| B | not A (B comes after A) | C | G | T | 3 | |
| D | not C (D comes after C) | A | G | T | ||
| H | not G (H comes after G) | A | C | T | ||
| V | not T (V comes after T and U) | A | C | G | ||
| N | any base (not a gap) | A | C | G | T | 4 |
See also
- Biology
- Chromosome
- Gene
- Genetics
- Nucleic acid analogues
- Nucleic acid sequence
- Nucleobase
References
^ abc Alberts B, Johnson A, Lewis J, Raff M, Roberts K & Walter P (2002). Molecular Biology of the Cell (4th ed.). Garland Science. .mw-parser-output cite.citationfont-style:inherit.mw-parser-output .citation qquotes:"""""""'""'".mw-parser-output .citation .cs1-lock-free abackground:url("//upload.wikimedia.org/wikipedia/commons/thumb/6/65/Lock-green.svg/9px-Lock-green.svg.png")no-repeat;background-position:right .1em center.mw-parser-output .citation .cs1-lock-limited a,.mw-parser-output .citation .cs1-lock-registration abackground:url("//upload.wikimedia.org/wikipedia/commons/thumb/d/d6/Lock-gray-alt-2.svg/9px-Lock-gray-alt-2.svg.png")no-repeat;background-position:right .1em center.mw-parser-output .citation .cs1-lock-subscription abackground:url("//upload.wikimedia.org/wikipedia/commons/thumb/a/aa/Lock-red-alt-2.svg/9px-Lock-red-alt-2.svg.png")no-repeat;background-position:right .1em center.mw-parser-output .cs1-subscription,.mw-parser-output .cs1-registrationcolor:#555.mw-parser-output .cs1-subscription span,.mw-parser-output .cs1-registration spanborder-bottom:1px dotted;cursor:help.mw-parser-output .cs1-ws-icon abackground:url("//upload.wikimedia.org/wikipedia/commons/thumb/4/4c/Wikisource-logo.svg/12px-Wikisource-logo.svg.png")no-repeat;background-position:right .1em center.mw-parser-output code.cs1-codecolor:inherit;background:inherit;border:inherit;padding:inherit.mw-parser-output .cs1-hidden-errordisplay:none;font-size:100%.mw-parser-output .cs1-visible-errorfont-size:100%.mw-parser-output .cs1-maintdisplay:none;color:#33aa33;margin-left:0.3em.mw-parser-output .cs1-subscription,.mw-parser-output .cs1-registration,.mw-parser-output .cs1-formatfont-size:95%.mw-parser-output .cs1-kern-left,.mw-parser-output .cs1-kern-wl-leftpadding-left:0.2em.mw-parser-output .cs1-kern-right,.mw-parser-output .cs1-kern-wl-rightpadding-right:0.2em
ISBN 0-8153-3218-1. pp. 120–121.
^ Coghill, Anne M.; Garson, Lorrin R., eds. (2006). The ACS style guide: effective communication of scientific information (3rd ed.). Washington, D.C.: American Chemical Society. p. 244. ISBN 978-0-8412-3999-9.
^ "Nucleotides". IUPAC Compendium of Chemical Terminology. IUPAC Gold Book. International Union of Pure and Applied Chemists. 2009. doi:10.1351/goldbook.N04255. ISBN 978-0-9678550-9-7. Retrieved 30 June 2014.
^ Lehninger, Albert L. (1975). "Biochemistry: the molecular basis of cell structure and function". Zeitschrift für Allgemeine Mikrobiologie. New York: Worth Publishers Inc. 17: 86–87. doi:10.1002/jobm.19770170116.
^ Stryer, Lubert (1988). Biochemistry (3rd ed.). New York: W. H. Freeman. ISBN 9780716719205.
^ Garrett, Reginald H.; Grisham, Charles M. (2007). Biochemistry (4th ed.). Belmont, California: Brooks/Cole, Cengage Learning.
^ Zaharevitz, DW; Anerson, LW; Manlinowski, NM; Hyman, R; Strong, JM; Cysyk, RL. "Contribution of de-novo and salvage synthesis to the uracil nucleotide pool in mouse tissues and tumors in vivo".
^ See IUPAC nomenclature of organic chemistry for details on carbon residue numbering
^ Jones, M. E. (1980). "Pyrimidine nucleotide biosynthesis in animals: Genes, enzymes, and regulation of UMP biosynthesis". Annu. Rev. Biochem. 49 (1): 253–79. doi:10.1146/annurev.bi.49.070180.001345. PMID 6105839.
^ McMurry, JE; Begley, TP (2005). The organic chemistry of biological pathways. Roberts & Company. ISBN 978-0-9747077-1-6.
^ Malyshev, Denis A.; Dhami, Kirandeep; Quach, Henry T.; Lavergne, Thomas; Ordoukhanian, Phillip (24 July 2012). "Efficient and sequence-independent replication of DNA containing a third base pair establishes a functional six-letter genetic alphabet". Proceedings of the National Academy of Sciences of the United States of America. 109 (30): 12005–12010. Bibcode:2012PNAS..10912005M. doi:10.1073/pnas.1205176109. PMC 3409741. PMID 22773812.
^ abc Malyshev, Denis A.; Dhami, Kirandeep; Lavergne, Thomas; Chen, Tingjian; Dai, Nan; Foster, Jeremy M.; Corrêa, Ivan R.; Romesberg, Floyd E. (May 7, 2014). "A semi-synthetic organism with an expanded genetic alphabet". Nature. 509 (7500): 385–8. Bibcode:2014Natur.509..385M. doi:10.1038/nature13314. PMC 4058825. PMID 24805238.
^ Callaway, Ewan (May 7, 2014). "Scientists Create First Living Organism With 'Artificial' DNA". Nature News. Huffington Post. Retrieved 8 May 2014.
^ ab Fikes, Bradley J. (May 8, 2014). "Life engineered with expanded genetic code". San Diego Union Tribune. Retrieved 8 May 2014.
^ Sample, Ian (May 7, 2014). "First life forms to pass on artificial DNA engineered by US scientists". The Guardian. Retrieved 8 May 2014.
^ Pollack, Andrew (May 7, 2014). "Scientists Add Letters to DNA's Alphabet, Raising Hope and Fear". New York Times. Retrieved 8 May 2014.
^ Mc Naughton, L.; Bentley, D.; Koeppel, P. (2007-03-01). "The effects of a nucleotide supplement on the immune and metabolic response to short term, high intensity exercise performance in trained male subjects". The Journal of Sports Medicine and Physical Fitness. 47 (1): 112–118. ISSN 0022-4707. PMID 17369807.
^ Riera, Joan; Pons, Victoria; Martinez-Puig, Daniel; Chetrit, Carlos; Tur, Josep A.; Pons, Antoni; Drobnic, Franchek (2013-04-08). "Dietary nucleotide improves markers of immune response to strenuous exercise under a cold environment". Journal of the International Society of Sports Nutrition. 10 (1): 20. doi:10.1186/1550-2783-10-20. PMC 3626726. PMID 23566489.
^ ab Nomenclature Committee of the International Union of Biochemistry (NC-IUB) (1984). "Nomenclature for Incompletely Specified Bases in Nucleic Acid Sequences". Retrieved 2008-02-04.
Further reading
Sigel, Astrid; Operschall, Bert P.; Sigel, Helmut (2017). "Chapter 11. Complex Formation of Lead(II) with Nucleotides and Their Constituents". In Astrid, S.; Helmut, S.; Sigel, R. K. O. Lead: Its Effects on Environment and Health. Metal Ions in Life Sciences. 17. de Gruyter. pp. 319–402. doi:10.1515/9783110434330-011. ISBN 9783110434330. PMID 28731304.
External links
Abbreviations and Symbols for Nucleic Acids, Polynucleotides and their Constituents (IUPAC)
Provisional Recommendations 2004 (IUPAC)- Chemistry explanation of nucleotide structure
Genetics | |
|---|---|
| *_Outline *_History *_Index">
| |
| Key components |
|
| Fields |
|
Archaeogenetics of |
|
| Related topics |
|
| |
Authority control |
|
|---|